Extract the efficiency of the matching between the shear catalog and the object catalog
Standard import
[1]:
import tables_io
import numpy as np
import hpmcm
import matplotlib.pyplot as plt
Set up the configuration
[2]:
keys = ['_cluster_stats'] # which tables to read
st_ = 'pgauss' # which catalog type
tract = 10463 # which tract to study
dd = tables_io.read(f"test_data/obj_{st_}_match_{tract}.pq", keys=keys)
data = dd['_cluster_stats']
column_list None
Make maskes of different types of matches
[3]:
good_mask = np.bitwise_and(data.nSrc ==2, data.nUnique ==2)
#in_tract = skymap.findTractIdArray(data.ra.values, data.dec.values, degrees=True) == 10463
in_tract = data.ra.values < 38.09
missing_md = np.bitwise_and(~good_mask, data.hasRefCat)
missing_ref = np.bitwise_and(~good_mask, ~data.hasRefCat)
extra = data.nSrc > 2
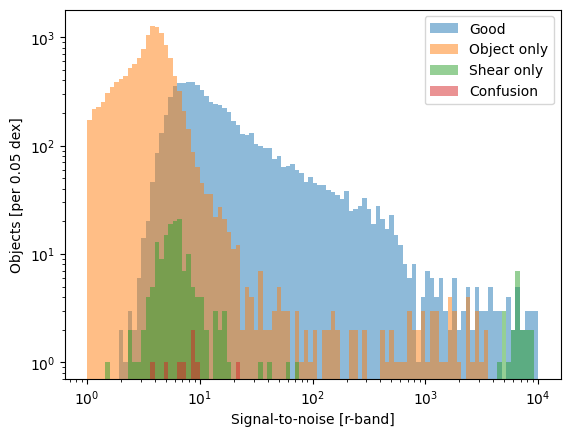
Make a histogram of the different match types
[4]:
_ = plt.hist(data[good_mask*in_tract].SNR, bins=np.logspace(0, 4, 101), alpha=0.5, label="Good")
_ = plt.hist(data[missing_md*in_tract].SNR, bins=np.logspace(0, 4, 101), alpha=0.5, label="Object only")
_ = plt.hist(data[missing_ref*in_tract].SNR, bins=np.logspace(0, 4, 101), alpha=0.5, label="Shear only")
_ = plt.hist(data[extra*in_tract].SNR, bins=np.logspace(0, 4, 101), alpha=0.5, label="Confusion")
_ = plt.xscale('log')
_ = plt.yscale('log')
_ = plt.legend()
_ = plt.xlabel("Signal-to-noise [r-band]")
_ = plt.ylabel("Objects [per 0.05 dex]")
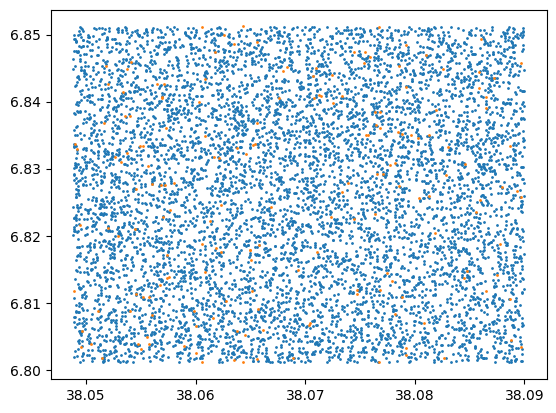
Make a scatter plot of positions of missing matches, to make sure we haven’t messed up the sky overlap
[5]:
_ = plt.scatter(data.ra[good_mask*in_tract], data.dec[good_mask*in_tract], s=1)
_ = plt.scatter(data.ra[missing_ref*in_tract], data.dec[missing_ref*in_tract], s=1)
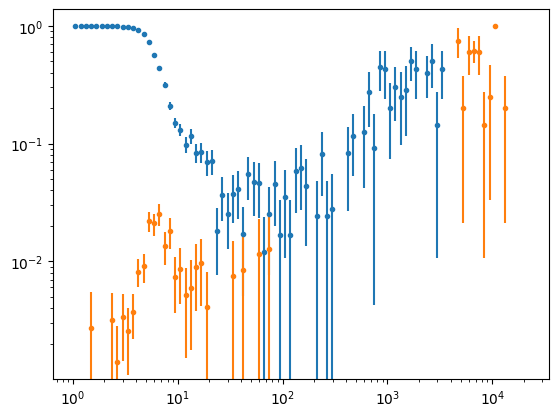
Estimate the good match efficiency as a function of SNR
[6]:
hist_all = np.histogram(data.iloc[in_tract].SNR, bins=np.logspace(0, 5, 101))[0]
hist_in_ref = np.histogram(data.iloc[data.hasRefCat.values*in_tract].SNR, bins=np.logspace(0, 5, 101))[0]
hist_missing_md = np.histogram(data.iloc[missing_md.values*in_tract].SNR, bins=np.logspace(0, 5, 101))[0]
hist_good = np.histogram(data.iloc[good_mask.values*in_tract].SNR, bins=np.logspace(0, 5, 101))[0]
hist_missing_ref = np.histogram(data.iloc[missing_ref.values*in_tract].SNR, bins=np.logspace(0, 5, 101))[0]
hist_in_md = hist_good + hist_missing_ref
hist_extra = np.histogram(data.iloc[extra.values*in_tract].SNR, bins=np.logspace(0, 5, 101))[0]
[7]:
ineffic_missing_md = hist_missing_md/hist_all
ineffic_missing_ref = hist_missing_ref/hist_all
ineffic_extra = hist_extra/hist_all
ineffic_ref_in_md = hist_missing_ref/hist_in_md
npq_missing_md = np.sqrt(ineffic_missing_md*(1-ineffic_missing_md)/hist_all)
npq_missing_ref = np.sqrt(ineffic_missing_ref*(1-ineffic_missing_ref)/hist_all)
npq_missing_extra = np.sqrt(ineffic_extra*(1-ineffic_extra)/hist_all)
npq_ref_in_md = np.sqrt(ineffic_ref_in_md*(1-ineffic_ref_in_md)/hist_in_md)
bin_edges = np.logspace(0, 5, 101)
bin_centers = np.sqrt(bin_edges[0:-1] * bin_edges[1:])
/tmp/ipykernel_1263/451252170.py:1: RuntimeWarning: invalid value encountered in divide
ineffic_missing_md = hist_missing_md/hist_all
/tmp/ipykernel_1263/451252170.py:2: RuntimeWarning: invalid value encountered in divide
ineffic_missing_ref = hist_missing_ref/hist_all
/tmp/ipykernel_1263/451252170.py:3: RuntimeWarning: invalid value encountered in divide
ineffic_extra = hist_extra/hist_all
/tmp/ipykernel_1263/451252170.py:4: RuntimeWarning: invalid value encountered in divide
ineffic_ref_in_md = hist_missing_ref/hist_in_md
Plot the good match efficiency as a function of SNR
[8]:
_ = plt.errorbar(bin_centers, ineffic_missing_md, yerr=npq_missing_md, label="Has Ref", ls="", marker='.')
_ = plt.errorbar(bin_centers, ineffic_missing_ref, yerr=npq_missing_ref, label="No Ref", ls="", marker='.')
_ = plt.xscale('log')
_ = plt.yscale('log')
Plot the good match efficiency w.r.t. the metadataect catalog as a function of SNR
[9]:
_ = plt.errorbar(bin_centers, ineffic_ref_in_md, yerr=npq_ref_in_md, label="Has Ref", ls="", marker='.')
_ = plt.xscale('log')
_ = plt.yscale('log')
_ = plt.xlabel("Signal-to-noise [r-band]")
_ = plt.ylabel("Inefficiency w.r.t. MD objects")
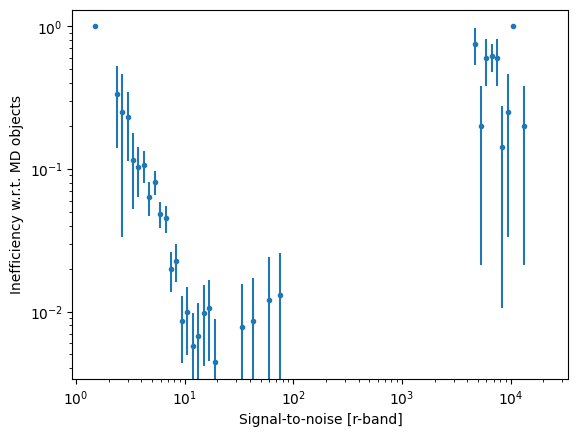
Estimate the good match efficiency w.r.t. the metadataect catalog
[10]:
nMissing = hist_missing_ref[20:].sum()
nAll = hist_in_md[20:].sum()
effic = (nAll-nMissing)/nAll
effic_err = np.sqrt(effic*(1-effic)/nAll)
[11]:
print(f"Effic: {effic:.5} +- {effic_err:.5f}")
Effic: 0.99022 +- 0.00152
[ ]:
[ ]: